ML in Project Management: Classification & Regression Problems with Text

At Forecast, we use machine learning (ML) to make project management easier and more efficient. To this end, we have in place several predictive models to automate and improve part of the decision-making. Our current models can automatically label tasks, assign resources and roles to them, and predict how long they are going to take. The models are served in the application in real-time to more than two hundred different companies and thousands of concurrent users.
In this article, we walk through some real examples of predictive models with text developed at Forecast, and how we solved the problems found along the way. We use pre-trained BERT type models to perform classification and regression tasks served in real time. Although the use of this technique is relatively widespread, there are many challenges related to industry setups for which there are no worked-out examples available. We provide solutions to some of these very common problems hoping to help others in a similar situation.
Predictive machine learning in project management
Predictive machine learning models are widely used across many industries; they are at the core of automation, and help in taking better decisions and personalized actions. Fairly simple models such as tree-based models or logistic regressions usually work well with tabular data. However, when it comes to unstructured data like the text it can be very challenging to extract all the signals there. For this purpose, the field of Natural Language Processing (NLP) has developed over the years many clever ideas to extract information from raw text.
During the past decade, NLP has seen pivotal breakthroughs thanks to the application of deep learning and novel architectures (RNNs, attention mechanisms, transformers) to language. Tasks like translation, question answering, or text prediction are now routinely performed by deep learning models served at scale (see some examples in Tensorflow here). These complex, state-of-art models that understand language can be repurposed to perform other tasks, being especially useful in the cases of classification and regression一the bread and butter of machine learning for many companies.
Setup
As mentioned before, we are currently serving four predictions in our application: we can recommend assignees, roles and labels, and predict minutes registered for all the tasks in a project.
At a given point, a task is characterized by many different features:
- Text features: title, description, comments
- Categorical features: company, project, role, assignees
- Numerical features: time registrations, deadline
The tasks are dynamic objects: users can modify them at all times from several places in the app. This means that the samples in our dataset (the rows) are updates in tasks, along with their current task status data.
Models
Data and architecture
We combine a pre-trained transformer layer with custom layers for classification and regression. The transformer layer is “fine-tuned” in the same training loop as the custom layers. This solution has been enthusiastically adopted in many set-ups as it offers state-of-art results with a relatively small pre-processing effort and moderate computational demands. The main drawback, however, is a higher difficulty in the set-up and tuning. There are excellent working examples of similar set-ups in the Tensorflow documentation.
The first challenge comes with the combination of text and structured data. In our case we have tried and implemented two solutions to the problem with similar performances:
- Encode the tabular features as text, and concatenate all of them in a single text input properly separating each feature with special tokens (names of the features).
- Design a neural network with multiple inputs. Concatenate the output of the transformer layer with the rest of inputs. There is a similar example with LSTMs in Keras documentation.
Next, we walk through the implementations in detail.
Classifiers
The classifier models currently being served predict the role required for a task, the next assignee, and the labels (user generated tags). To optimize resources and leverage all information available, we use a single instance of distilBERT layer shared by all classification tasks and all companies following a Multi-Task Learning (MTL) approach. MLT is an active field of research, usually compared to human learning, where knowledge about many tasks is collected over time. As a result, one can solve new tasks faster than if one should learn each individual task in isolation. A good summary of MTL can be found in this research paper.
The MTL approach gives us a larger training set, but in turn it slightly increases the accuracy of the model while reducing our serving cost by a factor three. The technical implementation of MTL amounts to sharing as much of the network as possible, and training the whole network and the output layers in one end-to-end process. This is achieved by introducing a masking layer just before the classification head allowing each input sample to only train one of the output layers, and blocking wrong error back-propagation to unrelated layers.
With this in place, we can serve improved models to our biggest customers. However, there is still one important issue: how should we ever be able to serve these large customer-specific transformer models to hundreds of customers each having their own set of assignees, roles, and labels. Our solution to this problem is to extend the task on/off switch to be an individual label on/off switch, thereby allowing us to train on the complete dataset increasing both accuracy, but also greatly reducing the sample size required for new customers to benefit from the solution.
The model architecture seen below takes in the tokenized words, and a mask for each classification output.
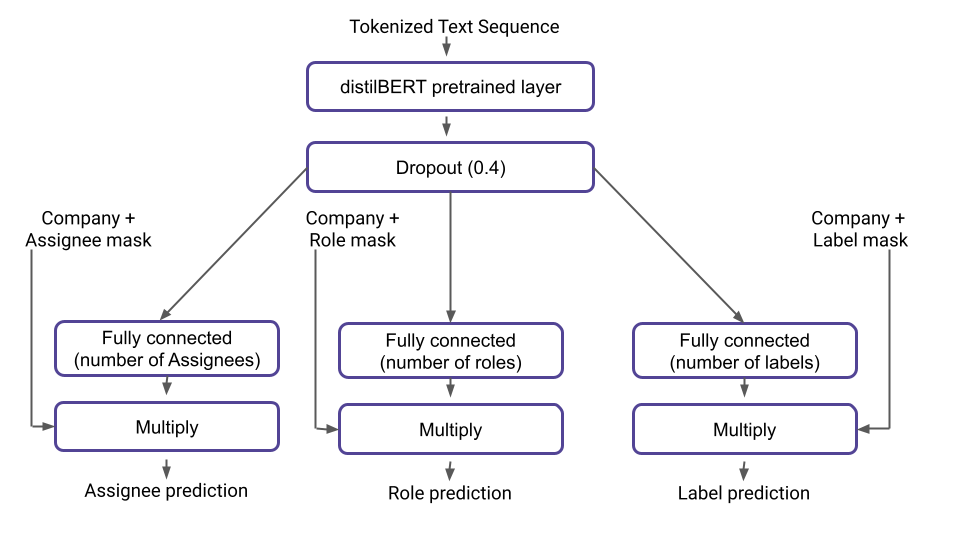
The mask is what allows us to train the network to have several independent classification heads (Assignee, Role, and Label) and for each head to have independent output classes per company. In later posts, we will explain in more detail how to construct these masks and also some other techniques we found important when dealing with an imbalanced dataset where the class balance shifts over time.
In this model, we add the tabular data like project and company name as text because this way of handling tabular features as text works surprisingly well. In a later post, we will go more into details about why we think this works well and the experiments we have done to handle tabular data in the more traditional sense like seen in the regressor model below.
In most machine learning solutions there is a trade-off between model size and accuracy. In this particular case, we feel we have found a good balance. By using distilBERT we get close to state-of-the-art accuracy in the text embedding and by sharing this layer across companies and tasks. We both get increased accuracy, while also reducing the serving cost compared with smaller task and customer-specific network that was previously in production.
Regressor
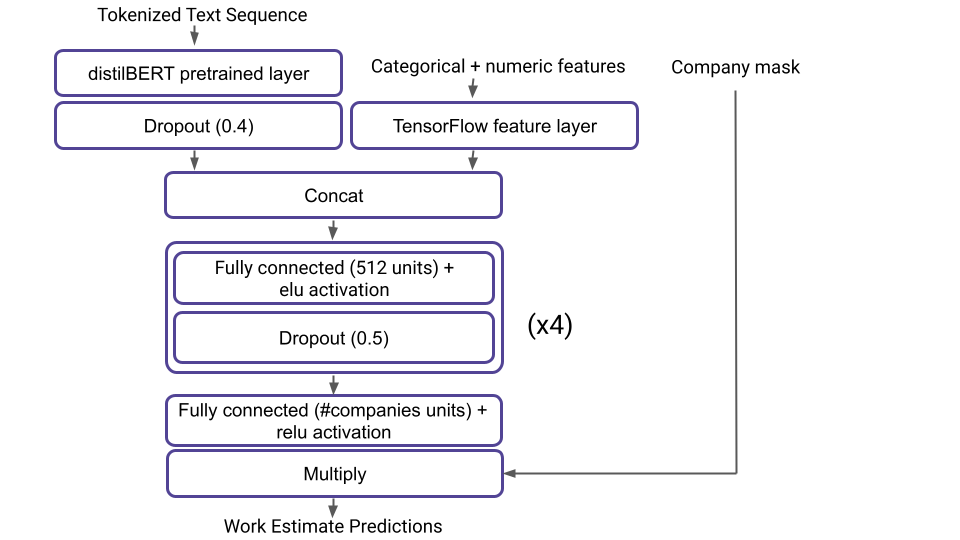
We also implemented a regressor model to predict the total minutes registered in a task once it is finished. Upon trying the “only text” vs “text + other variables” input strategies, we find the latter has a slightly better performance. It is interesting to note that the example provided in the Keras documentation has only one layer after the concatenation of the embedding and the features. In our setup, this architecture has poor performance, needing up to four layers to surpass the “only BERT” approach.
The architecture of the model is rather simple. We use the TensorFlow “feature layer” to ingest the non-text features and concatenate the resulting tensors to the embeddings outputted by the distilBERT layer. Several fully connected layers are applied afterward, culminating with a positive defined “regression” layer thanks to a relu activation.
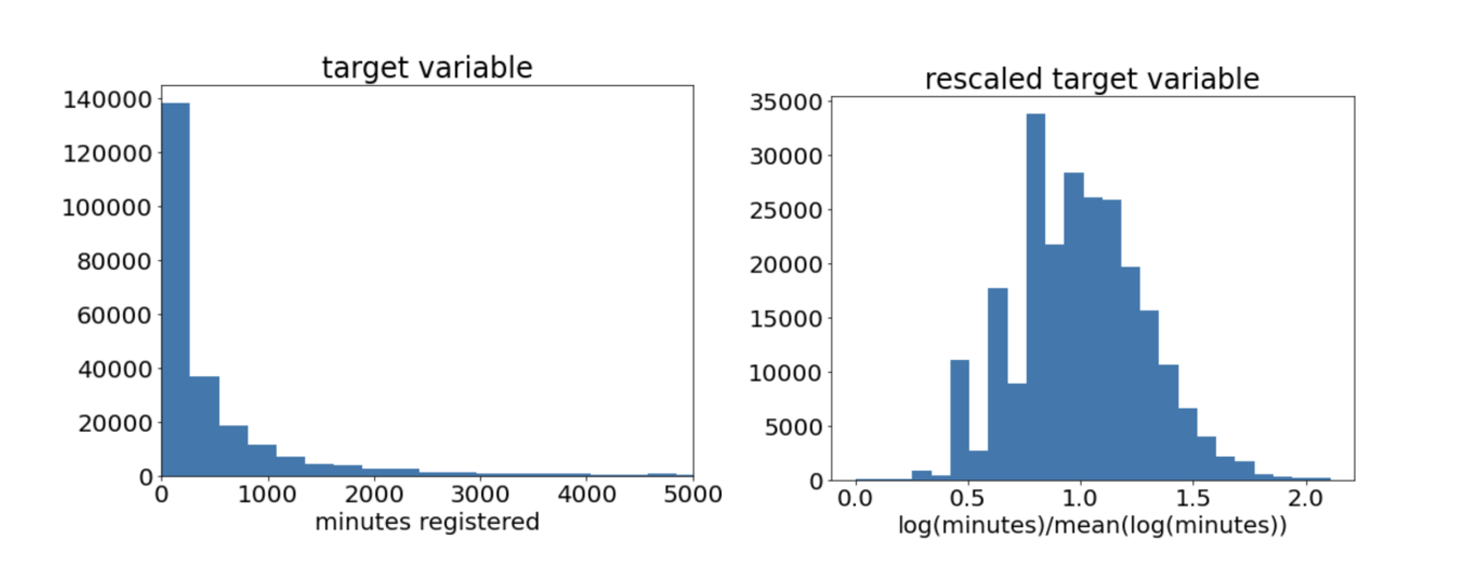
One of the challenges in the regression case is the normalization of the target variable. This number can vary greatly across projects and companies, and it spans several orders of magnitude. This kind of very skewed distribution is very suitable for logarithmic normalization. The rescaled distribution will be a bell-shaped distribution that one can normalize to help the neural network converge faster (typical initializations require input and output values to be around one). As a bonus, the logarithmic normalization will convert the MSE loss into a penalty on the relative error and will not be so much biased by very large values in the target variable.
Conclusions
In this post, we have shown how one can use modern deep learning architectures to build predictive models with text in a real industry setup. We do tackle academic questions such as combining text and other variables, Multi-Task Learning, or targets spanning many orders of magnitude, but also we deal with practical challenges like the limitation of resources and serving many different companies at the same time.
Coming Up
- Is it all just text: How BERT handled categorical features as text input, and our experience with a more classical text and categorical features approach.
- Together is better: How does Multi-Task Learning increase accuracy, and how training data can be pooled while still giving independent predictions pr. company.
- Be fair to the newcomers: How to increase the production accuracy in a changing domain, when using historical data for model training.
- Save the climate: Tips and tricks to speed up training, and minimizing serving cost when working with larger deep learning models.
